日々進化するHadoop。これまでのおさらいと最近の動向(前編)
大規模な分散処理フレームワークとしてHadoopが登場したことにより、ビッグデータのブームや、大規模なソーシャルゲームでのログ解析による改善、コマースサイトでの機械学習によるレコメンデーションなど、多くの変化が引き起こされてきました。
そしてそのHadoop自体も、日々進化し続けています。
Hadoopとはどういうソフトウェアであり、いまどのような状況になっているのか。NTTデータの濱野賢一朗氏が、先日行われた第2回 NHNテクノロジーカンファレンスで行ったセッション「日々進化するHadoopの『いま』」で分かりやすく解説しています。
この記事ではそのセッションの内容をダイジェストで紹介しましょう。
日々進化するHadoopの「いま」
NTTデータ 基盤システム事業部 濱野賢一朗氏。
NTTデータというところで仕事をしています。NTTデータ自体はもう5年くらいHadoopをやってまして、そこで27~28人くらいHadoopをやっている人がいるのですが、そのとりまとめに近いことをやっています。

Hadoopって何なのかというと基本的には2つのコンポーネント、分散ファイルシステムの「HDFS」(Hadoop Distributed File System)、大規模分散処理フレームワークの「MapReduce」でできています。
Hadoopの基本的なアイデアは、ひとつのハードディスクドライブで出せるスループットでは限界があるので、ハードディスクドライブを持った複数のIAサーバを分散配置すれば大規模なデータもどんと読み込めて高速にできるだろうと。
これを支えているのが分散ファイルシステムのHDFSです。このデータを処理するときもローカリティを活かして、極力そのデータがあるサーバの中で処理するようにしています。

また分散処理固有の問題、例えばサーバが壊れたり、ネットワークが遅延したり、部分的に処理が失敗したものを検出してリカバリするのはMapReduceフレームワークの方で解決してもらって、プログラマは考えなくていいようにしています。
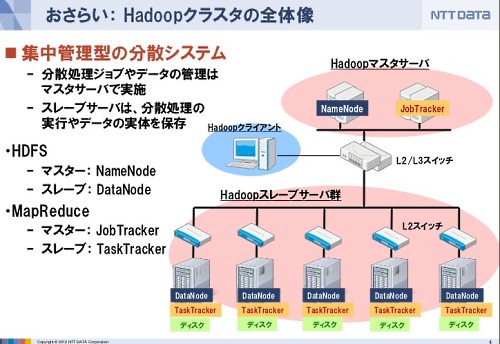
マスターとスレーブに分かれるHDFS
物理的にはこういうアーキテクチャになっていて、マスターサーバとスレーブサーバに分かれた集中管理型になっています。
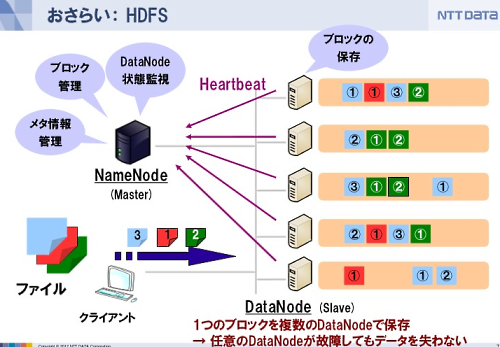
ひとつのデータを格納しようとするとHDFSのスレーブ、DataNodeに格納されます。大きなデータは64MBくらいの単位に分けて分散したサーバに配置されます。
また、サーバが故障したときのために同じデータを複数のサーバが重複して持っています。
マスターサーバは、データを置いているDataNodeがどういう状態になっているか、といったことを管理しています。
MapReduceは分散処理フレームワーク
MapReduceは何かというと、例えば商品が売れたときの伝票があってどの商品がいくら売れたかを集計するときには、商品ごとに分けた伝票の山を作って、その山ごとに伝票の中身を足し合わせて計算すると思います。
それをある意味でアルゴリズムに落としたのがMapReduceです。
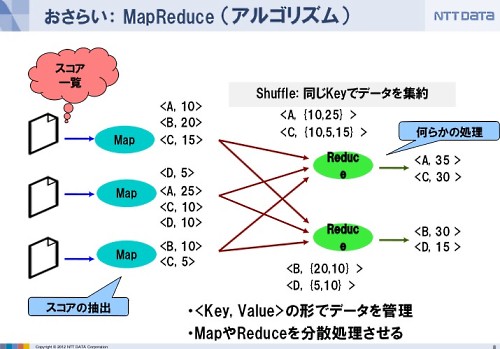
これのいいところは、伝票がたくさんあったときにそれを分割して複数の人がそれぞれ商品別に分ける作業が並行してできるわけです。例えば伝票の商品別仕分けを3人でやると、それぞれ3人の前に、商品Aの伝票の山や商品Bの伝票の山など、商品別伝票の山ができます。
そして商品ごとの売り上げを集計するときには、商品Aの山をみんなからがさがさと集めて「お前が集計しろよ」と渡して集計し、商品Bの山もがさがさと集めて「これはお前ね」と渡して集計する、集計もそれぞれ独立して計算できる。というところがひとつの特徴です。
すなわちMapの処理も、Reduceの処理も並行して実行することが可能。これが並列処理がうまくできているポイントの一部です。
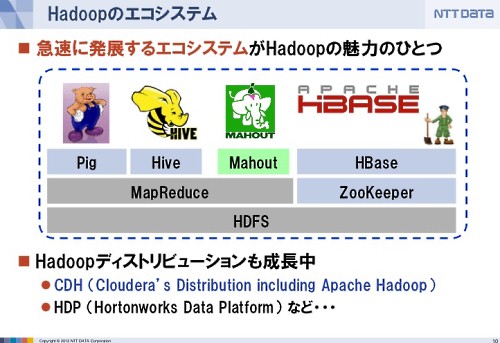
エコシステムの発展もHadoopの魅力
Hadoopの魅力のひとつは、たぶん周辺のソフトウェアというかエコシステムが発展していることだと思います。いろんな周辺ソフトウェアがでてきています。
現状メジャーなHadoopのディストリビューションはClouderaの「CDH」(Cloudera's Distribution including Apache Hadoop)と呼ばれるものですが、それ以外にもディストリビューションはいくつか存在します。