
NoSQLとHadoopを、オラクルは企業が使うデータベースとしてどう位置づけようとしているのか?
「NoSQLはソーシャルメディアのようなネットアプリケーション向けであり、企業内のデータベースとしては向かない」。これまでNoSQLデータベースは一般にそう思われていました。
しかしオラクルは今月、サンフランシスコで開催した「Oracle OpenWorld 2011」でビッグデータ市場への参入を表明。製品として、企業向けデータベースとしてキーバリュー型データストア「Oracle NoSQL Database」と「Apache Hadoop」を搭載した「Oracle Big Data Appliance」を発表しました。
オラクルは企業が使うデータベースとしてNoSQLやHadoopをどのように位置づけようとしているのでしょうか?
昨日10月25日に都内で開催された日本オラクル主催のイベント「Oracle Database/Exadata Summit」において、米オラクルでデータベース製品開発総責任者のアンディ・メンデルソン氏が、同社のビッグデータ戦略におけるNoSQLデータベースやHadoopの役割について解説を行いました。

大規模データのバックエンドとしてのNoSQL
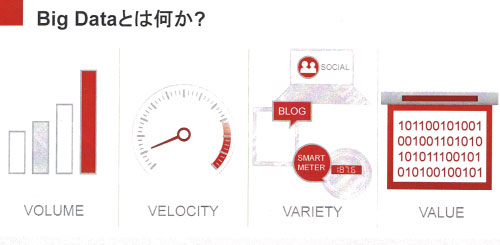
メンデルソン氏は、ビッグデータとはデータの「ボリューム」と「増加速度」(Velocity)だけでなく、ソーシャルネットワークのテキストデータや、デバイスから生成される位置データなど「データの種類」、そして「無意味なデータと価値あるデータが混在している」のが特徴だと説明。
「例えば心臓病の患者の心臓モニターデータのほとんどは正常値。大事なのは心臓に変調を感じたときのわずかなデータでしかない」と、ビッグデータでは大量のデータの中から価値のある一部分を抜き出すことの重要性を強調します。
オラクルはこの、大規模で急速に増加し、多種にわたるビッグデータを収集するアプリケーションのバックエンドとしてNoSQLデータベースの「Oracle NoSQL Database」を位置づけています。
そして大量データの中から意味のあるデータを抜き出し、フォーマットなどを揃えてデータウェアハウスへ転送するのが「Apache Hadoop」によるMapReduce処理。この処理を容易に記述するツールとして「Oracle Loader for Hadoop」を提供しています。
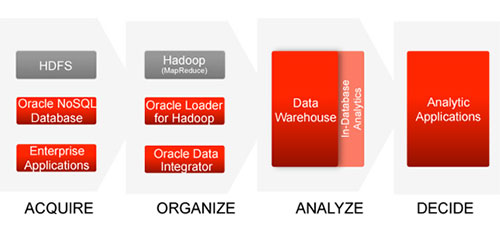
データウェアハウスに格納されたデータは、分析ツールやBIツールなどによってレポートやダシュボードに分析結果が表示されることになります。ここで核となっているデータベースは、従来のリレーショナルデータベースです。
生のビッグデータはNoSQL、分析はリレーショナルDB
オラクルは、データを分析する主役はリレーショナルデータベースを中心としたデータウェアハウスにあり、その手前の処理としてビッグデータを保存し、処理するソフトウェアとしてNoSQLデータベースとHadoopを位置づけているわけです。
既存のリレーショナルデータベースを中心としながら、ビッグデータのような新しい現象に対して新しい技術のNoSQLデータベースやHadoopで対応するというのは、オラクルらしいアプローチでしょう。
あわせて読みたい
ZendがAmazonクラウドでPHPが使えるPaaS「phpcloud.com」を発表
≪前の記事
オラクルがNoSQLに本気。エンタープライズ向け「Oracle NoSQL Database 11g」公開。オープンソース版も登場

