
Twitterの大規模システム運用技術、あるいはクジラの腹の中(前編)~ログの科学的な分析と、Twitterの「ダークモード」
先週の6月22日から、米サンタクララで行われていたWebサイトのパフォーマンスと運用に関するオライリーのイベント「Velocity 2010」が開催されていました。
その中で、TwitterのJohn Adams氏がTwitterのシステム運用について説明するセッション「In the Belly of the Whale: Operations at Twitter」(クジラの腹の中:Twitterでの運用)が行われています。Twitterのような大規模かつリアルタイムなWebサイトの運用とはどういうものなのでしょうか?
公開されているセッションの内容を基に概要を記事で紹介しましょう。システム管理者の新たな役割、Railsの性能の評価、Bittorrentを使ったデプロイなど、新たな発見が数多くあるはずです。
ワールドカップ日本代表を上回ったレイカーズの2連覇
John Adams氏。Twitterの初期から参加しており、アプリケーションサービスのリードエンジニアだと自己紹介。

Twitterは現在、従業員が210名。

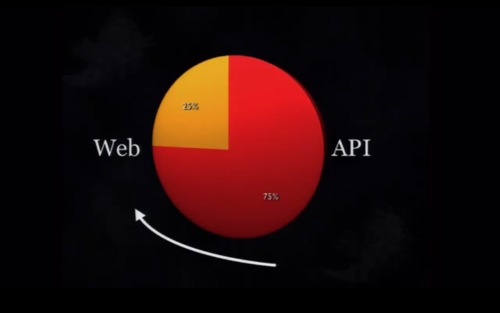
Twitterへのアクセスは、API経由が75%でさらに上昇中。
1日に6500万ツイートされており、1秒間だと約750ツイート。

最大負荷の瞬間は、ワールドカップで日本代表が得点したときの、秒間2940ツイートだったが、これを先日NBAで2連覇を達成したレイカーズが優勝したときの秒間3085ツイートが上回った。

オペレーションチームの役割
オペレーションチームは、こうしたピークのときも、ふだんのときも運用を担当しつつ、キャパシティプランニングを行い、性能を改善し、クジラの発現を減らそうとしている。

Webサイトの利用者数が500から数百万、数千万に増えると、最初に考えていた設計は有効ではなくなる。ある規模で有効な策は、その規模でしか有効ではないことを学んだ。サイトの設計を何度も考え直さなければならなかった。私たちはいまでもそうして何度もやりなおしている。

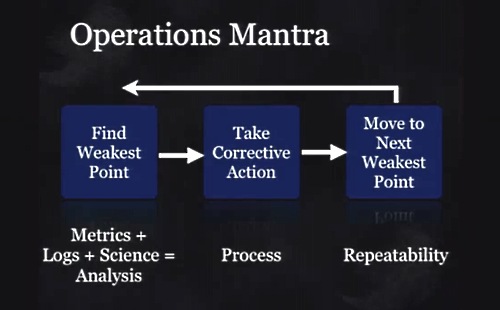
オペレーションチームの最大の役割は、まずMTTD(Mean Time To Detect)、問題発見までの時間をできるだけ短く、問題を素早く発見し、MTTR(Mean Time To Recovery)、リカバリを短時間に行わなければならない。
そのためにはこのマントラ、計測、ログ(記録)、科学的な分析、システム改善、ボトルネックの排除、を何度も繰り返していく。
システム管理は「Sysadmin 2.0」という新しい役割へ
「モニタリング」は、Webサイトに何が起きているかを理解するために非常に重要だ。Twitterは重要なメトリクスをほとんどリアルタイムにモニタしている。もしもあなたがAPI経由でTwitterにアクセスするアプリケーションを開発しているのなら、同じようにデータを集めてTwitterとアプリケーション間でどのような通信が起きているのかモニタすべきだ。

こうした作業の中で私は、システム管理者には大きな変化が起きているのだ、ということを発見した。これを「Sysadmin 2.0」と呼んでいる。Sysadmin 2.0はデータを集め、数学や科学的手法を用いてこれを分析し、何が起きているのかをデータを基に判断する、という役割を果たす。

Twitterでどのようなデータを集めているかといえば、Aapche、Rubyなどについてのローレベルなデータ、レイテンシ、メモリリークなど。使っているのはtcpdumpとtcpdstat、yconalyzerなどだ。

きっと多くの人がRailsの性能の問題について聞いたことがあると思うけれど、私たちが経験した性能の面での問題についてRubyが直接関係したことはなかった。ガベージコレクション、レプリケーションラグ、SQLの問題、ほとんどはこれらが原因だった。

ログをとるためのsyslogは、高負荷な環境では役に立たないことが分かった。syslogデーモンがダウンすれば何のデータもとれなくなってしまう。
障害が起きているときのログを分析することはとても大事だ。そこでFacebookのオープンソースのScribeとHDFSへと移行した。大規模な分析はHadoopで行っている(参考記事:Facebookが大規模スケーラビリティへの挑戦で学んだこと(前編)~800億枚の写真データとPHPのスケーラビリティ問題)。

ダッシュボードとダークモード
「ダッシュボード」が、つねにモニタリングで最初に見る画面だ。ここで何が起きているのか、10個程度の重要なメトリクスについて見ている。ほかにもマーケティング部門はGoogle Analyticsも使っている。
うまく行ったのがシェルスクリプトで作った「Whale Watcher」スクリプトだ。Twitterのエラーとして、HTTP 503(Timeout)が発生するとクジラの画面が表れて、HTTP 500(error)のときはロボットの画面が表れる。過去60秒のあいだにこれらがどれだけ起きたかを集計してグラフ化している。これがとても役立っている。

昨年、多くの時間を費やしてデプロイプロセスを改善し、コードをより素早く、しかもエラーの発生を少なくデプロイするようにした。
コードをデプロイするときには、リリースの前に機能をブロックする「Darkmode」を使う。Twitterを使っていて、ある機能が追加されたと思ったら元に戻った、といった経験があるだろう。
Darkmodeには、90もの機能を停止するスイッチがある。これは非常に強力で、たとえプロダクション状態であっても障害から回復するために機能をオフにすることができる。

後編「Twitterの大規模システム運用技術、あるいはクジラの腹の中(後編)~Twitterのサブシステム「Unicorn」「Kestrel」「Flock DB」」に続く。
関連記事
Twitterがログを科学的に分析してボトルネックを発見し、問題解決を行ったときの具体的な様子は、次の記事で紹介しています。
また、Twitterが開発したフレームワーク「Gizzard」の解説は以下です。
大規模システムの運用については、Facebookの事例も詳細に解説した記事を過去に掲載しています。
あわせて読みたい
Twitterの大規模システム運用技術、あるいはクジラの腹の中(後編)~Twitterのサブシステム「Unicorn」「Kestrel」「Flock DB」
≪前の記事
Red Hat Summit 2010 「クラウドのロックインをオープンソースで解いていく」戦略。JBOSSはRuby、PHPもサポートへ

