
Facebook、memcachedに300TB以上のライブデータを置く大規模運用の内側
クラウドのように大規模なシステムでは、ソフトウェアの開発と同等以上に、大規模運用の巧拙が、システム全体の成功を大きく左右します。
6月22日から、米サンタクララで行われていたWebサイトのパフォーマンスと運用に関するオライリーのイベント「Velocity 2010」で、FacebookのTechnical Operations teamを担当するTom Cook氏が「A Day in the Life of Facebook Operations」(Facebook運用のある1日)と題したセッションで、Facebookがふだんどのような運用を行っているか、紹介しています。
世界でトップクラスの大規模サイトが、普段どのようなツールを用い、どのような方法で運用しているのか、セッションの内容を紹介しましょう。
6年で4億アクティブユーザー、3カ所のデータセンター

Tom Cook氏。Facebookは現在、毎週60億のコンテンツが共有され、毎月30億枚の写真がアップロードされている。また、FacebookはFacebook.comのWebサイトだけでなく、100万のFacebook Connectアプリケーションが実装されている。ある調査では、Webサイトの上位400サイトのウチ半分はFacebookと連係しているそうだ。
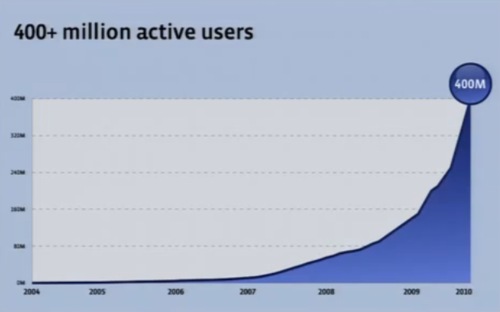
そしてFacebookはわずか6年で4億アクティブユーザーとなり、このうちの15%は毎日アクセスしている。急速に成長しているWebサイトだ。
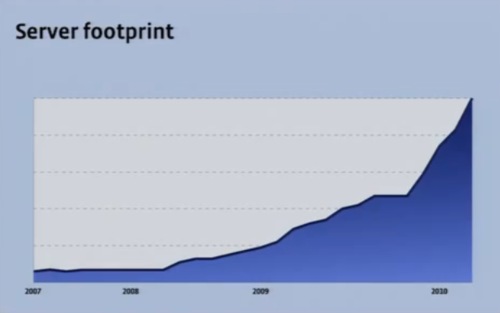
Facebookは、ハーバードにいたMark Zuckerbergの一室で、1台のサーバからはじまった。やがて人気が出て機能を追加し、サーバを増やしていった。
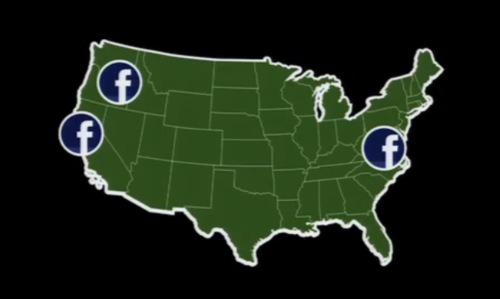
いま、ベイエリアとバージニアの2カ所に大規模なデータセンターがあり、そしてもうすぐオレゴンにも新しいデータセンターができあがるところだ。
Facebookのソフトウェア構成は純粋なLAMPスタックとなっている。Facebookで使っている主なソフトウェアを紹介していこう。
Hiphop for PHP
HipHop for PHPは、ソースコードトランスフォーマーだ。デベロッパーはPHPで開発し、それをC/C++に変換してg++でコンパイルする。
Hiphopは3人のエンジニアによって書かれ、いまはFacebookのあらゆるトラフィックを処理している。これによって15%のCPU利用量を削減できた。
Memcached
データベースとWebサーバのあいだのキャッシュ。Facebookでは現在、300TB以上のライブデータをMemcachedにいれている。
MySQL
Facebookでは、ShardingしたMySQLによってデータベースを保存している。
こうしたソフトウェアのスタックはこのようになっている。
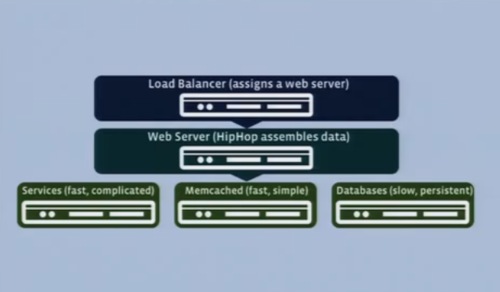
コンフィグレーション管理、デプロイメント、モニタリング
Facebookでは、このインフラのうえでアプリケーションを構築している。そして今日話そうとしているのは、これをどうやって運用しているか、ということ。デプロイメント、モニタリングといったシステム管理運用の話だ。
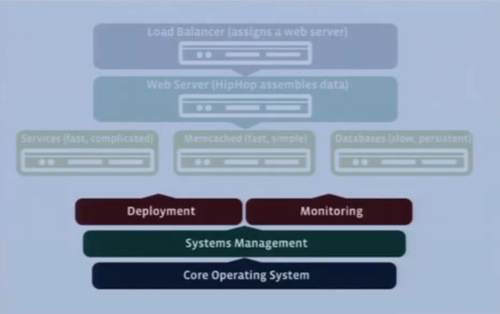
いちばん下のOperationg Systemでは、Facebook全体でLinuxを採用している。カスタマイズしたカーネル2.6。
システム全体を安定した環境として管理するのに使っているのは、コンフィグレーションマネジメントとオンデマンドツールの2つ。
もしも何らかのインフラを管理しているのなら、コンフィグレーションマネジメントをしなければならない。これが効果的なスケールを実現している。
CFengine
コンフィグレーションマネジメントのツールとして、CFengineを利用している。FacebookはCFengineの最大規模のユーザーだろう。私たちは15分ごとにサービスをアップデートしている。15分ごとに数百のポリシーを評価し、数千のルールを実行するというのをだいたい30秒で行っている。
On-Demand control tool
オンデマンドの管理ツールでは、オープンソースに私たちのニーズに合致するものはなかった。内部的なツールを使っており、これについては詳しくお話できない。
続いて、デプロイメントについて紹介しよう。
フロントエンドに対するデプロイはWeb Pushという技術で行っている。Facebookではこれを使って、日に1~2回のパッチやバグフィックス、週に1度程度の新機能のデプロイを行っている。
Web Pushは前述のOn-Demand control toolの上に作られており、BitTorrentでコードがディストリビューションされる。非常に高速で、約1分で数百MBが、数万のフロントエンドサーバすべてに届く。このデプロイはサーバのリスタートは伴わない、ファイルの配布のみ用いる。
(参考:BitTorrentでのデプロイはTwitterでも行われています。詳しくは記事「Twitterの大規模システム運用技術、あるいはクジラの腹の中(後編)」をご参照ください)。

バックエンドのデプロイメントについては、これとは違う方法で行っている。通常の組織では、Engineering / QA / Operations(開発、品質管理、運用)は分かれている。エンジニアはコードを書き、QAがそれを確認して、というのは多くのコミュニケーションを必要とする。
そこで私たちはエンジニアにQAを担当させることにした。エンジニアはコードを書き、テストし、デバッグし、デプロイするのだ。エンジニアはコードを書いてテストしデプロイするという、サービスのライフタイム全体に責任を持つ。
オペレーション担当もエンジニアチームの中にいて、エンジニアがなにを必要か理解し、アーキテクチャに関するエンジニアの判断を助けている。

Change Loggingも重要だ。Facebookのソフトウェアに対するすべての操作はログに残る。これで、問題が起きたときでも何が変わったのか、誰が変えたのかすぐ分かるようになった。ロギングシステムをつねに動かしている。
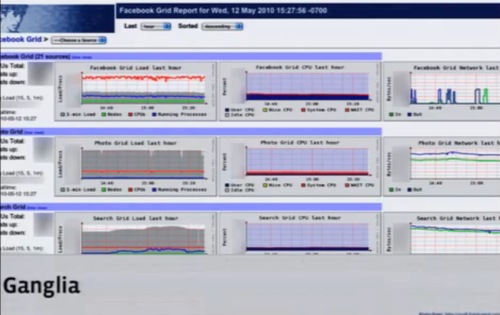
システムのモニタリングにはGangliaを使っている。
Gangliaは非常に高速で、グリッドやプールのネストができる。いま500万ものメトリックスをGangliaでチェックしている。そして問題があったら、この画面からドリルダウンしていける。
ODSも使っている。Gangliaはシステムにフォーカスしているが、ODSはアプリケーションにフォーカスしている。ODSはGangliaの補完的な位置づけであり、一貫性が高く正確。一方のGangliaは高速でおおまか、という違いがある。またNagiosも利用している。
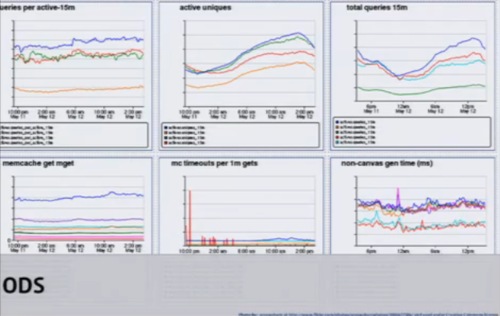
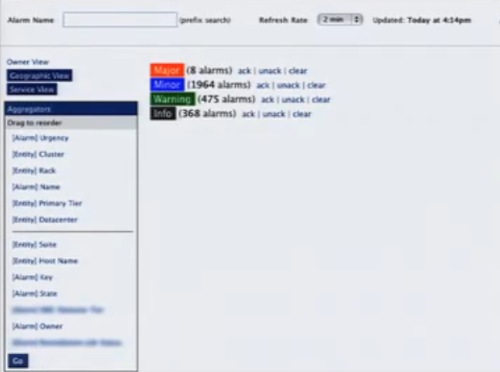
システムからのアラームなどはあまりに多いため、アグリゲーション(統合)してある。それを必要に応じてデータセンターごと、アプリケーションごとにドリルダウンして見ている。あるいはエンジニアリングチームごとに。これは、インターナルな自動化ツールで行っている。
これのマイナーアラート(青い部分)をクリックするとデータセンターごとに展開され、クラスタごとに展開され、ラックごとに展開してみることができる。さらに、サービスごと、ティアごと、ホストごとに見ることができる。
緊密な社員同士のコミュニケーションを支えるツール
私たちは社内で社員同士の緊密なコミュニケーションを行っている。特にIRCはヘビーに使っており、自動化したボットでステータスの変化、何か変わったことの通知などもしている。
内部的なニュースポータルも情報の共有に使っている。何か大きな変更があった場合にはヘッダバナーで知らせることもある。それから小さなチームであることも効果を発揮している。

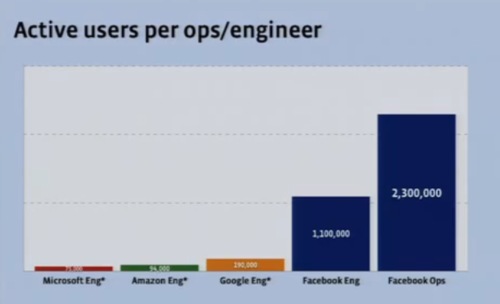
エンジニアごとのアクティブユーザーを比べると、Facebookは1エンジニアあたりのユーザー数が非常に多いが、それだけでなく運用担当者あたりのユーザー数も非常に多い。
まとめよう。
とにかく何でもバージョンコントロールを行い、変化を記録することだそして、運用サイトから言えば、早い段階からオプティマイズをすること。徹底的に自動化し、サーバが多くてもコンフィグレーションマネジメントを欠かさないこと。
障害に備え、そしてあらゆるものを使いこなす。くだらないことに時間をとられないようにすること。運用は革新のブロッカーになりやすい。エンジニアができるかぎり早く革新ができるように、安定した環境を作り出すことが大事だ。

関連記事
Twitterの運用について紹介した記事もぜひご参照ください。
- Twitterの大規模システム運用技術、あるいはクジラの腹の中(前編)~ログの科学的な分析と、Twitterの「ダークモード」
- Twitterの大規模システム運用技術、あるいはクジラの腹の中(後編)~Twitterのサブシステム「Unicorn」「Kestrel」「Flock DB」
大規模データセンターでは、1人あたりが管理するサーバが数千台にもなるそうです。

