
セールスフォースのアーキテクチャ(物理アーキテクチャ編)~ Podによるスケールアウト
米国の計算機学会として知られるACMが主催したクラウドコンピューティングのシンポジウム「ACM Symposium on Cloud Computing 2010」(ACM SOCC 2010)が6月10日、11日にインディアナ州インディアナポリスで開催されました。
基調講演には、グーグル、Facebook、セールスフォース・ドットコムというクラウド業界のトップベンダーが登場し、それぞれのクラウドについて語るという内容でした。ここではその基調講演から、セールスフォース・ドットコムのRob Woollen氏による同社クラウドのアーキテクチャの解説を紹介します。おそらくこれまででもっとも詳しく、同社のクラウドアーキテクチャを解説したものになっています。
セールスフォースのマルチテナントアーキテクチャとは
Rob Woollen氏。講演タイトルは「Inside Cloud:Salesforce.com's Multi-tenant Architecture」(クラウドの内側、セールスフォース・ドットコムのマルチテナントアーキテクチャ)。

まずはセールスフォースのアーキテクチャ概要を紹介しよう。
セールスフォースのすべてのユーザーはユーザー名を持ち、そのユーザー名は特定の「テナント」と結びついている。テナントとは企業のような組織のことだ。この組織は1ユーザーから数万ユーザーの場合までさまざまである。
コンシューマクラウドとは異なるエンタープライズクラウドの特徴は、テナントによって区切られていることだ。この区切りを効果的に行うことがスケーラビリティのカギとなる。
そしてこのクラウドは、ただ1つの、シングルコードベースのプロダクションサービスである。クラウド上では1つのバージョンのソフトウェアが稼働している。データベースの管理者であるDBAはわずか8人だ。
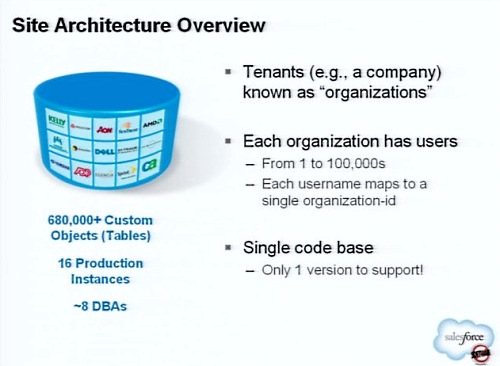
物理的なアーキテクチャをみてみよう。
セールスフォースのユーザーは組織に属すると先ほど説明した。その組織はいずれかのインスタンスに割り当てられる。インスタンスとはクラウドを構成するハードウェアとソフトウェアの集まりだ。
データベース、アプリケーションサーバ、ロードバランサー、ストレージ、オブジェクトストアやコンテンツマネジメントなどから構成される一連のユニットが「インスタンス」である。
これらのインスタンスは「Pod」と呼ばれる。Podは現在、北米、EMEA(欧州、中東、アフリカ)、アジア太平洋地域に配置されており、それぞれのテナントはこれらの「Pod」と呼ばれるインスタンスのいずれかに割り当てられる。
以下の図では、NA1(North America 1)からNA3までのPodが描かれているが、現在NA0からNA7までのPodが稼働しており、ユーザーの増加に合わせて数カ月以内にはNA8がリリースされる予定だ。新しくサインアップするユーザーにはNA8が割り当てられることになる。
Podは、クラウドをスケールアウトする基本的な方法として採用している。
しかしこれだけでは効果的ではないので、次に行うのが「スプリット」だ。既存のPodを2つやそれ以上の新しいPodに分割する。通常はハードウェアによる増強を選択するためスプリットすることは滅多にないが、Podがキャパシティの限界にきたときにはスプリットを行うことがある。
さらにほとんど起こらないことではあるが、スケールアウトのための3番目の選択肢として個別のテナントをマイグレーションすることがある。例えば、大企業がセールスフォースを部門で導入したあとで、全社展開するようなときがこれにあたる。この場合、より容量の大きなPodへと移行することがある。
内部で利用しているソフトウェアは、メインのデータベースとしてOracle RAC(Real Application Clusters)を利用しており、アプリケーションサーバとしてはオープンソースのResinを、サーチエンジンとしてLuceneを、OSとしてはLinuxであるRed Hatを採用している。
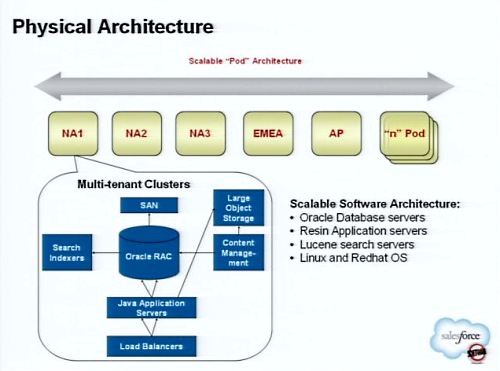
セールスフォースでは、数十万のユーザーすべてが同じインフラストラクチャを共有している。このことを簡単に数字で紹介しよう。
私たちは、わずか15のデータベース、数百台のサーバ、そして1つのコードを組み合わせることによって、(CRMのSalesforceだけでなく、Force.comの上で開発された)十万種類のユニークなアプリケーションのプラットフォームを実現しているのだ(注:今年の6月にマーク・ベニオフCEOは、サーバは3000台だと説明しています)。
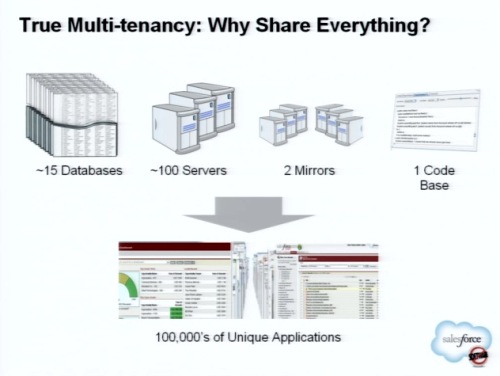
このクラウドの内部の説明に移ろう。ストレージ階層におけるキャッシュについて。
セールスフォースは内部で2つのモデルのキャッシングを備えている。1つはノントランザクショナルキャッシュ。おおむね最新のデータを保持しているが、トランザクションは保証されていない。
もう1つがトランザクションアウェアキャッシュ。トランザクションがなければ、ビジネスユーザーが望むデータの整合性が保証されないことはお分かりと思う。
このキャッシュは3つに分かれている。
L0キャッシュは、Javaアプリケーションサーバ内のスレッド内のキャッシュ。ビジネスアプリケーションのリクエストは頻繁に同じ一連の情報にアクセスすることが多いため、その際にはこのキャッシュが使われる。
L1キャッシュは、Javaアプリケーションサーバのプロセス内のヒープ領域にあるキャッシュ。スレッドローカルキャッシュよりも大きい。
L2キャッシュは、memcachedによるサーバ間にまたがるより大きな分散キャッシュサービス。このうえにトランザクションアウェアキャッシュを構築している。
トランザクションアウェアキャッシュへのリクエスト時には、トランザクション開始時に一貫性のチェックが行われる。平均して数ミリセカンドでチェックは終わる。
キャッシュのヒット率は約99.5%で、わずか0.5%程度の割合でメタデータが変更されており、リロードが発生することがある。
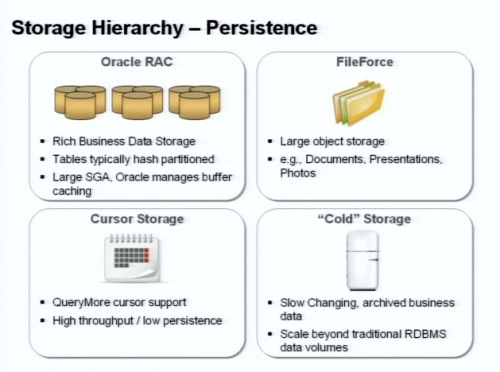
続いてストレージ階層における永続性(パーシステンス)について。
私たちはOracle RACのヘビーユーザーであり、8wayデータベースを運用してビジネスユーザーのデータを保存している。
データベースへのアクセスはほとんどキャッシュ経由で、実際にデータへのアクセスが発生しても、Oracleのバッファキャッシュ(SGA)を大幅に活用している。
またデータのパーティショニングにも大きく依存している。データベースは組織IDをキーとしてパーティショニングされている。
一方で、ドキュメントやプレゼンテーション、写真や画像と言った大きなオブジェクトのストレージとして、HTTPベースのクラウドファイルシステムを用意している。
カーソルストレージは高スループットを要求するようなアプリケーションの用途のため用意された。というのも、クラウドのデータベースで問題となるのは、カーソルを使って大量のデータへアクセスしているときに、クライアントとの接続が切れてしまうことが発生することだ(大量のデータにアクセス中のカーソルが、クライアントを失ってリソースを抱えたまま宙ぶらりんの状態になってしまうため)。
そこでカーソルがデータを読み込んだら、カーソルストレージを用意してそのデータをここへ格納してしまう。こういう特定用途のためのストレージだ。
サーバやデータベースを共有しつつ、これまで説明した機能を用いてどのようにマルチテナントを実現しているのか、それを説明しよう。
まずサービスの分離だ。マルチテナントの内部では、企業Aのデータと企業Bのデータをどのように切り離すかが大きな課題となる。たとえクラウド内部でバグなどが発生したとしても、企業(テナント)の境界を越えてデータが漏洩してしまうことはあってはならないからだ。
実行中のアプリケーションが持つ組織IDおよびユーザーIDは、スレッドローカル(スレッドが独立したオブジェクトを持ち、操作する)となっており、Javaのレベルでなりすましてほかの組織や個人のデータを参照できないようにしている。
利用者がデータベースへクエリを実行するときに、自分の組織以外のデータが参照できないように、クエリが生成されるときに必ず組織IDによってデータがフィルタリングされるようになっている。SOQL(セールスフォース独自の問い合わせ言語)実行時に、自動的にこの条件が内部で追加される仕組みで実現している。
セールスフォース・ドットコム社内のデベロッパーも、テナントのデータを参照できない制限がかかっている。私たちが社内でSQLをコンパイルしたときには、正確性と効率性のための静的な分析が行われるルールになっており、組織IDのフィルタがないクエリにはフラグがたつため自動的に把握することができる。
また実行されたクエリに対してもログとして記録され、ルール違反がないかチェックされるため、動的にクエリを構築して実行したとしてもチェックが働くようになっている。

データの分離に続いて、サービスの分離についても説明しよう。さまざまなテナントが同じハードとソフトを共有しているとき、あるテナントがリソースを消費しすぎないように、フェアに使うにはどうするか。
セールスフォースのプログラミング言語「Apex」では、「ガバナリミット」を設定している。これはインタプリタのレベルで、テナントに割り当てるヒープやスタックの大きさ、無限ループの実行などを制限している。また、データベースに対して一度に数千行のデータを操作しようとすると、その実行も制限される。
また、Apexコードをデプロイするときにも制限がある。80%程度のカバレッジを持つユニットテストにパスしたコードでなければデプロイできないようになっている。
また、セールスフォース自身のクラウドのコードがアップデートリリースされるときには、ユーザーのコードを新リリースに対してテストし、リグレッションが起きていないかどうかといったことがチェックできる。このことは、デベロッパーとセールスフォース・ドットコム双方にとってのメリットとなる。

次回「セールスフォースのアーキテクチャ(マルチテナントデータベース編)~ Flex Schemaとオプティマイザ」に続く。
記事「セールスフォースのアーキテクチャ」
- セールスフォースのアーキテクチャ(物理アーキテクチャ編)~ Podによるスケールアウト
- セールスフォースのアーキテクチャ(マルチテナントデータベース編)~ Flex Schemaとオプティマイザ
- セールスフォースのアーキテクチャ(シングルコード編)~ セールスフォースの内部コードで見る、過去との互換性をどう保つか
関連記事
次回のデータベース編を読む前に、マルチテナントアーキテクチャのデータベース周りを解説した以下の記事に目を通していただくと、より理解が深まります。
あわせて読みたい
セールスフォースのアーキテクチャ(マルチテナントデータベース編)~ Flex Schemaとオプティマイザ
≪前の記事
ライブドアのBLOGOSに掲載されると、トラフィックはどれだけ上昇するか?

