
Facebookが大規模スケーラビリティへの挑戦で学んだこと(前編)~800億枚の写真データとPHPのスケーラビリティ問題
全世界で3億人を超える会員を抱え、世界最大のSNSとなったFacebook。同社の巨大なシステムは、3つのデータセンターにある約3万台のサーバと、PHP、C++、Memcache、MySQLなどのソフトウェア群によって支えられています(同社のデータセンターの巨大さは、記事「3億のユーザーを抱えるFacebookのデータセンター。移動は自転車、希望は100Gbイーサネット 」を参照)。
同社の技術担当バイスプレジデント Jeff Rothschild氏は、Facebookが実現している大規模なスケーラビリティを、いかにしてこれらのソフトウェアで実現しているのか、10月8日に米カリフォルニア大学サンディエゴ校で行ったセミナー「High Performance at Massive Scale-Lessons learned at Facebook」で解説しました。
そこでは、キャッシュテクノロジーを中心としていかにスケーラビリティを実現するか、そしてその際の課題をどのように解決してきたのか、興味深い内容が語られています。セミナーの様子はビデオキャストで誰でも参照することができますが、この記事ではその内容からポイントになる部分を再構成して紹介しましょう。
ここからの文章は、Rothschild氏がセミナーで話したことをまとめたものです。
3万台のサーバに対してエンジニアは230人
このセミナーではFacebookがこれまで直面した課題をどう克服してきたかを説明しようと思う。Facebookは世界最大級のWebサイトの1つで、1カ月に200ビリオン(2000億)ページビューで、300ミリオン(3億)人のアクティブユーザーが1日に1ビリオン(10億)のチャット、1日に100ミリオン(1億)の検索などを実行している。
 Facebook vice president of technology Jeff Rothschild氏。セミナーは優秀な大学生をリクルーティングする目的も含まれていたようだ
Facebook vice president of technology Jeff Rothschild氏。セミナーは優秀な大学生をリクルーティングする目的も含まれていたようだしかも利用者が信じられないほど飛躍的に増加してきた。また、今年は会社にとって重要なマイルストーンを経験した。4月に会社がプロフィッタブル(単月黒字)になり、現在でもポジティブなキャッシュフローを維持している。
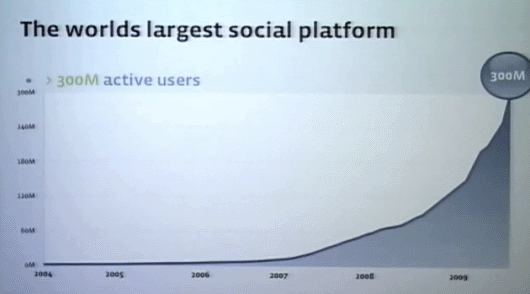
Facebookの中心はエンジニアリングだが、2005年に会員が約200万人だったとき、社内のエンジニアはわずか2人しかいなかった。しかもその1人は創業者のMark Zuckerbergだ。そして現在、社内のエンジニアチームは230人になった。
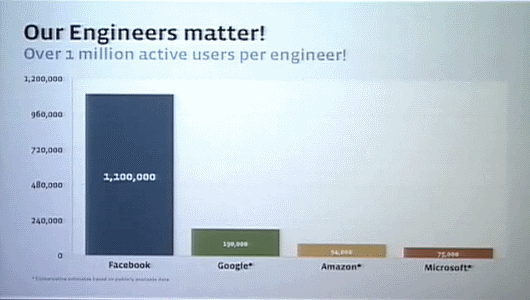
Facebook のアクティブユーザー数で社内のエンジニア数を割ると、だいたい110万アクティブユーザーに対して1人のエンジニア、ということになる。これはほかのインターネット企業と比べれば極端に少ないエンジニア数だといえる。われわれはこれを今後もさらに向上させていこうと思っている。
ディスクの物理I/Oが限界を決める
さて。SNSのソーシャルグラフは、人だけでなく、企業や製品やカンパニーや友達のブログポストやビデオや写真など、それぞれがどのように関係しているかを示している。大量のデータとともにそのあいだのリレーションシップがソーシャルグラフとして発生している。これら複雑に関係した大量のデータをどうやって保存し、表現するかがFacebookにとってのチャレンジだ。
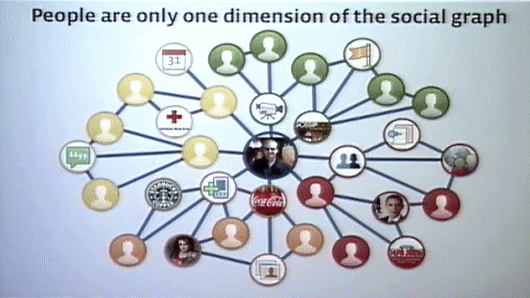
ネット上にはたくさんの写真がある。写真を構成するイメージデータは大きく、しかもFacebookに保存された写真はソーシャルグラフで結びついている。例えば、誰かが写真をFacebookにアップロードしてタグを付けると、その人のソーシャルグラフで結びついている人には、写真が公開されたという知らせをFacebookから受け取ることになる。
Facebookには約20ビリオン(200億)枚の写真が保存されており、それぞれが4種類の解像度で保存されているため、全体で800億枚の写真が保存されているといえる。これは写真を全部つなぐと地球を10回包むだけの面積がある。

技術的なチャレンジは、大量のデータを保存するだけでなく、それをユーザーにデリバリ(表示)しなければならない点だ。Facebookでは、一秒間に60万枚の写真を表示しており、ここがもっとも難しい点である。
しかしわれわれのような小規模な会社では社内のリソースだけで問題を全部解決することはできない。スキルのある社内のエンジニアを、大量の写真を表示するためのバックエンド部分の問題解決に投入するべきか、それともユニークな新機能を開発するのに投入するべきか選ばなければならない。答えは明らかだ。優秀なエンジニアはユニークな機能の開発に投入し、他社と技術的な課題がオーバーラップする部分はソリューションを購入すればいい。そこで我々は簡単な方法を選ぶことにした。NFSストレージ製品を購入したのだ。
ところが、そのファイルシステムは大量のファイルをサポートするのに向いておらず、データはファイルキャッシュに収まらず、ストレージ容量よりもI/Oの多さによって性能が限界を迎えてしまった。
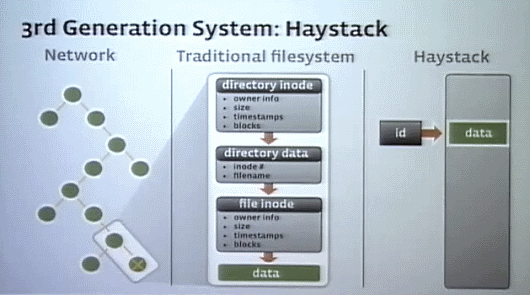
大量の写真データを扱うとき、ディスクの物理I/Oが性能の限界を決める。調査してみると、1つの写真を取り出すのに10回もの物理I/Oが行われていた。データは複雑なディレクトリの中に格納され、ファイルキャッシュメモリは大量の写真データのためにほとんど役に立っていなかった。
そこでまず、ファイルメタデータの扱いやディレクトリの構造、ブロックサイズなどについて最適化を行い、物理I/Oを2~4回程度までに減らした。
さらに、独自のHeystackと呼ばれるオーバーレイファイルシステムを構築した。これは多くの写真データを集めてそれらをOSからは1つのファイルのように見せかけ、メタデータはキャッシュするなどの仕組みを持つ。これでほとんどの場合1回の物理I/Oで写真データを取り出せるようになった(グラフ右の写真はHaystackの開発チーム)。

Haystackはオープンソースでできている。我々はオープンソースを強く信じている。
プレゼンテーションレイヤはPHPでプログラミング
Facebookのアーキテクチャはほかのサイトとそれほど変わらない。ロードバランサーがWebサーバの手前にあり、Webサーバの裏にサービス群、フィード、サーチ、広告、そしてキャッシングやデータベースレイヤがある。
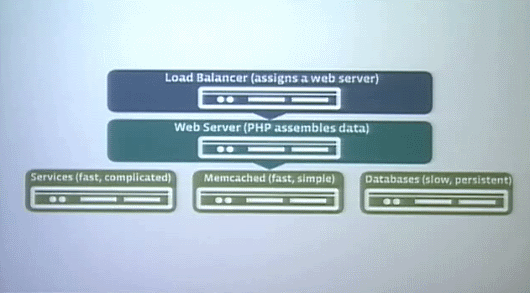
さて。Webサーバの部分を見てみよう。Webサーバで動作するプログラムはPHPを使っている。
PHP を選んだ理由は、シンプルな言語で学びやすいからだ。書くのも簡単だし、読むのもデバッグも簡単。一方で、ダークサイドもある、ランタイムコストだ。 CPUとメモリの消費が大きいし、ほかの言語と統合するのも難しい。また大規模なプロジェクトでは、モジュール構造をうまくサポートしているとはいえない。
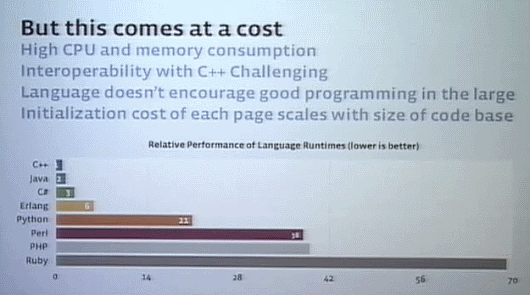
それ以外にも、長い経験から発見したPHPの課題がある。新しく書いたコードが古いコードを遅くするということだ。例えば、PHPで書いたABCという機能にDEFという新機能を付け加えると、たとえABCからDEFを呼び出していなかったとしてもABCの動作が以前より遅くなるのだ。初期化コストなどが増加するためだ。PHPにはこうしたスケーラビリティの課題がある。

そこでわれわれは、PHPの初期化を緩和するためのの拡張であるLazy loadingや、Cache priming、最近ではPHPをC++にコンパイルするといったアプローチを採用している。
バックエンドの開発用にフレームワークを用意
Facebookはバックエンドで多くのサービスが動作している。バックエンドサービスの構築にはPHPは使わず、C++を使うことが多いが、それ以外にも複数の言語を用いて開発している。

サービスの構築を容易にするため、バックエンドサービス用のサービスフレームワークを開発した。
Thrift
Thriftはオープンソースのプロジェクトとして開発しているクロスランゲージのフレームワークで、RPC環境を提供する。Facebookでは、サービスのタスクごとに適切な言語を選んでライブラリを作り、それをRPCで呼んでいる。

Thriftはライトウェイトなフレームワークとして作られ、シリアライゼーション、コネクションハンドリングなどを気にせずに済むベーシックなテンプレートを提供してくれる。必要なサーバ機能はフレームワークが提供してくれる。
Scribe
Scribeは分散したデータを中央のデータベースに集約するフレームワークだ。その例の1つとして、UNIXのログであるsyslogを集めて管理する仕組みも作った。
各マシンのログをキューイングしながら統合し、巨大な1つのシーケンシャルなログに変換してくれる。このScribeもThriftの上に構築されている。
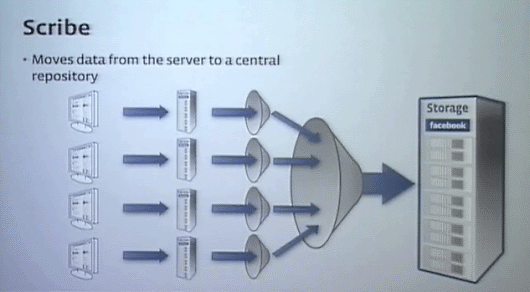
Scribeでトラフィックを処理するのに少数のサーバで済む非常に効率的な方法だ。サービスをコンフィグレーションしたりモニタするシステムも、これらの上で作られている。
(「Facebookが大規模スケーラビリティへの挑戦で学んだこと(後編)~キャッシュが抱えるスケーラビリティの問題とデータセンターにまたがる一貫性」へ続く)
スケーラビリティに関連する記事
これまでにPublickeyで公開した、クラウドのスケーラビリティに関連する記事も参照してみませんか?
あわせて読みたい
Facebookが大規模スケーラビリティへの挑戦で学んだこと(後編)~キャッシュが抱えるスケーラビリティの問題とデータセンターにまたがる一貫性
≪前の記事
「納期を半分にしてくれ、金なら出す」

